
In the previous article, I introduced three estimation methods of Randomized Response: Maximum Likelihood, Gibbs Sampling and Collapsed Variational Bayesian.
I implemented and experimented with these methods in Python.
- iir/privacy/randomized-response at master · shuyo/iir · GitHub
- rr-mle.py
- Maximum Likelihood Estimation
- rr-gibbs.py
- Gibbs Sampling
- rr-vb.py
- Collapsed Variational Bayes
- rr-mle.py
rr-mle.py and rr-gibbs.py draw the result as charts after 10000 trials.
rr-vb.py separates inference trials and result drawing because of the very long execution time.
$ python rr-vb.py 100 # 1000 inference trials (parallel execution)
$ python rr-vb.py # result reportOn a survey with 

Maximum Likelihood Estimation (MLE)



These figures are histograms of the 10000 estimates from randomized answers.
MLE has the same variance regardless of the true value because they are solutions to a linear equation. The smaller N, the larger the variance, so it may have more than 1 or a negative estimate.
Gibbs Sampling (GS)



These figures are histograms of 10000 Gibbs Sampling estimates (average of last 200 samples) with a prior parameter 
There is almost no difference between MLE and GS when N is large enough.
On the other hand, the Bayesian model is effective when N is small and MLE estimate may be negative. In MLE, estimates may be negative, but it is with in the positive range in Gibbs Sampling estimation. Its variance is also smaller than MLE’s.
 for N=100 for N=100 | MLE | GS 1.0 | GS 0.1 | GS 0.01 |
![\mathbb{E}[\hat\pi_1]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Chat%5Cpi_1%5D&bg=ffffff&fg=666666&s=0&c=20201002) | 0.10 | 0.18 | 0.13 | 0.11 |
![{\rm stddev}[\hat\pi_1]](https://s0.wp.com/latex.php?latex=%7B%5Crm+stddev%7D%5B%5Chat%5Cpi_1%5D&bg=ffffff&fg=666666&s=0&c=20201002) | 0.21 | 0.09 | 0.18 | 0.26 |
In Bayesian model, the estimates tends to be leveled from the true value due to regularization effect of prior. The above table is the mean and standard deviation of the esitmate 
In Gibbs Sampling with 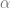


These figures are histograms with 
It remains even with N=1000.
Collapsed Variational Bayesian (VB)



These figures are histograms of 10000 estimates on Collapsed Variational Bayesian with a prior parameter
The results of GS and VB look the same in the above figures, but VB has a smaller variance. The boxplots of estimates 



In all cases, VB(each left) has smaller variances than GS(each right). The standard deviations are written at the horizontal axis label.
In GS, there was a problem that estimates tend to degenerate when a prior parameter is small. What about VB?


The effect of prior remains for N=100, but “ordinary estimates” are obtained. The boxplot makes this clearer.



On GS, 
VB also has smaller variances than GS for large N, so it is available to balance leveling and variance by choosing the appropriate a prior parameter.
 be a random variable of a survey’s answer
be a random variable of a survey’s answer 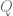 with
with 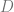 choices, and
choices, and  be a randomized version of
be a randomized version of 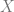 .
Then Randomized Response model is the following.
.
Then Randomized Response model is the following.
 has a Dirichlet conjugate prior with a hyperparameter
has a Dirichlet conjugate prior with a hyperparameter  .
.
 individuals answer
individuals answer  for the survey and send their randomized values
for the survey and send their randomized values  to a curator. The curator estimates some statistics like
to a curator. The curator estimates some statistics like ![\mathbb{E}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX%5D&bg=ffffff&fg=666666&s=0&c=20201002) from
from  .
.
 : Maximum Likelihood Estimation, Gibbs Sampling, and Collapsed Variational Bayes.
: Maximum Likelihood Estimation, Gibbs Sampling, and Collapsed Variational Bayes. be counts of observation
be counts of observation 
 , the estimator of
, the estimator of  .
.
 ,
,  be
be  minus
minus  :
: .
.

 .
. are randomly initialized and iteratively sampled from distribution (1) & (2), Let estimator
are randomly initialized and iteratively sampled from distribution (1) & (2), Let estimator  as the following:
as the following: .
.![\begin{aligned} & \mathcal{F}\left(q(\boldsymbol{X},\boldsymbol{\pi})\right)\\ =\;& \mathbb{E}_{q(\boldsymbol{X},\boldsymbol{\pi})} [ -\log P(\boldsymbol{Y},\boldsymbol{X},\boldsymbol{\pi}) ] - \mathcal{H}(q(\boldsymbol{X},\boldsymbol{\pi})) \\ =\;& \mathbb{E}_{q(\boldsymbol{X})} [ \mathbb{E}_{q(\boldsymbol{\pi}|\boldsymbol{X})} [ -\log P(\boldsymbol{Y},\boldsymbol{X},\boldsymbol{\pi}) ] - \mathcal{H}(q(\boldsymbol{\pi}|\boldsymbol{X})) ] - \mathcal{H}(q(\boldsymbol{X}))\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%26+%5Cmathcal%7BF%7D%5Cleft%28q%28%5Cboldsymbol%7BX%7D%2C%5Cboldsymbol%7B%5Cpi%7D%29%5Cright%29%5C%5C+%3D%5C%3B%26+%5Cmathbb%7BE%7D_%7Bq%28%5Cboldsymbol%7BX%7D%2C%5Cboldsymbol%7B%5Cpi%7D%29%7D+%5B+-%5Clog+P%28%5Cboldsymbol%7BY%7D%2C%5Cboldsymbol%7BX%7D%2C%5Cboldsymbol%7B%5Cpi%7D%29+%5D+-+%5Cmathcal%7BH%7D%28q%28%5Cboldsymbol%7BX%7D%2C%5Cboldsymbol%7B%5Cpi%7D%29%29+%5C%5C+%3D%5C%3B%26+%5Cmathbb%7BE%7D_%7Bq%28%5Cboldsymbol%7BX%7D%29%7D+%5B+%5Cmathbb%7BE%7D_%7Bq%28%5Cboldsymbol%7B%5Cpi%7D%7C%5Cboldsymbol%7BX%7D%29%7D+%5B+-%5Clog+P%28%5Cboldsymbol%7BY%7D%2C%5Cboldsymbol%7BX%7D%2C%5Cboldsymbol%7B%5Cpi%7D%29+%5D+-+%5Cmathcal%7BH%7D%28q%28%5Cboldsymbol%7B%5Cpi%7D%7C%5Cboldsymbol%7BX%7D%29%29+%5D+-+%5Cmathcal%7BH%7D%28q%28%5Cboldsymbol%7BX%7D%29%29%5Cend%7Baligned%7D+&bg=ffffff&fg=666666&s=1&c=20201002)
 with
with  and then with
and then with  . Let
. Let  .
.![\mathcal{F}\left(q(\boldsymbol{X})\right) = \mathbb{E}_{q(\boldsymbol{X})} [ -\log P(\boldsymbol{Y},\boldsymbol{X}) ] - \mathcal{H}(q(\boldsymbol{X}))](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%7D%5Cleft%28q%28%5Cboldsymbol%7BX%7D%29%5Cright%29+%3D+%5Cmathbb%7BE%7D_%7Bq%28%5Cboldsymbol%7BX%7D%29%7D+%5B+-%5Clog+P%28%5Cboldsymbol%7BY%7D%2C%5Cboldsymbol%7BX%7D%29+%5D+-+%5Cmathcal%7BH%7D%28q%28%5Cboldsymbol%7BX%7D%29%29&bg=ffffff&fg=666666&s=1&c=20201002)
 with each
with each  .
. be the parameter of the multinominal
be the parameter of the multinominal  and
and  ,
,  ( where
( where  is an indicator function), then the update function is the following:
is an indicator function), then the update function is the following:![\begin{aligned}\gamma_{ni} \propto\;& \exp\left( \mathbb{E} _ {q(\boldsymbol{X}^{-n})} [ \log P(\boldsymbol{Y},\boldsymbol{X}^{-n},X _ n=i) ]\right) \\ \propto\;& \exp\left( \log P(Y_n|X_n=i) + \mathbb{E} _ {q(\boldsymbol{X}^{-n})} \left[ \log \int \pi_i \prod_k \pi_k^{\alpha_k+c_k^{-n}-1}d\boldsymbol{\pi} \right]\right) \\ \propto\;& \exp\left( \log p_{iY_n} + \mathbb{E}_{q(\boldsymbol{X}^{-n})} \left[ \log (\alpha_i+c_i^{-n}) \right]\right) \\ \approx\;& p _ {iY_n}(\alpha_i+\gamma_i^{-n})\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cgamma_%7Bni%7D+%5Cpropto%5C%3B%26+%5Cexp%5Cleft%28+%5Cmathbb%7BE%7D+_+%7Bq%28%5Cboldsymbol%7BX%7D%5E%7B-n%7D%29%7D+%5B+%5Clog+P%28%5Cboldsymbol%7BY%7D%2C%5Cboldsymbol%7BX%7D%5E%7B-n%7D%2CX+_+n%3Di%29+%5D%5Cright%29+%5C%5C+%5Cpropto%5C%3B%26+%5Cexp%5Cleft%28+%5Clog+P%28Y_n%7CX_n%3Di%29+%2B+%5Cmathbb%7BE%7D+_+%7Bq%28%5Cboldsymbol%7BX%7D%5E%7B-n%7D%29%7D+%5Cleft%5B+%5Clog+%5Cint+%5Cpi_i+%5Cprod_k+%5Cpi_k%5E%7B%5Calpha_k%2Bc_k%5E%7B-n%7D-1%7Dd%5Cboldsymbol%7B%5Cpi%7D+%5Cright%5D%5Cright%29+%5C%5C+%5Cpropto%5C%3B%26+%5Cexp%5Cleft%28+%5Clog+p_%7BiY_n%7D+%2B+%5Cmathbb%7BE%7D_%7Bq%28%5Cboldsymbol%7BX%7D%5E%7B-n%7D%29%7D+%5Cleft%5B+%5Clog+%28%5Calpha_i%2Bc_i%5E%7B-n%7D%29+%5Cright%5D%5Cright%29+%5C%5C+%5Capprox%5C%3B%26+p+_+%7BiY_n%7D%28%5Calpha_i%2B%5Cgamma_i%5E%7B-n%7D%29%5Cend%7Baligned%7D&bg=ffffff&fg=666666&s=1&c=20201002)
 has
has  -local differential privacy if
-local differential privacy if  for all
for all  and any
and any  . This
. This  . Then Randomized Response with the design matrix
. Then Randomized Response with the design matrix  .
.
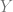 is
is  .
. 